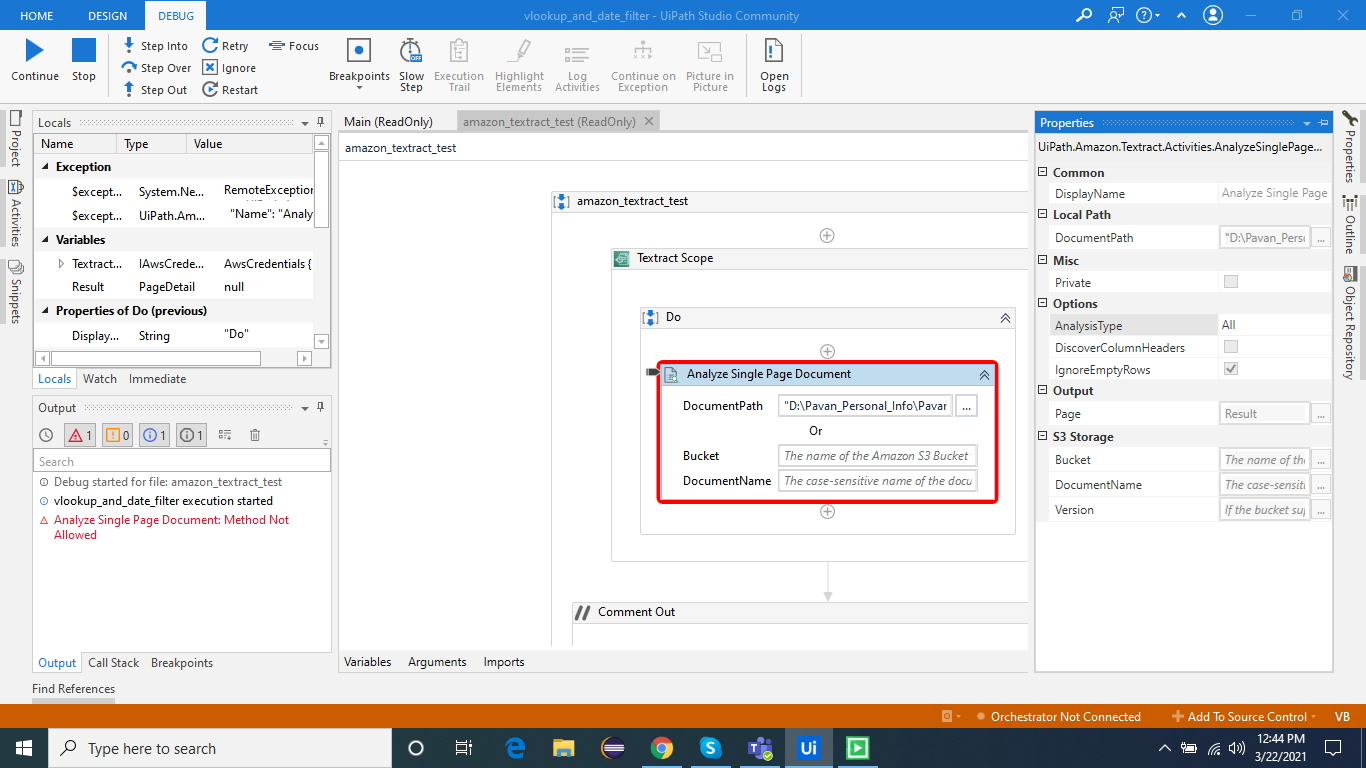
I am trying to use aws textract recognition for one of the images using uipath, I am using analyze single Page doc activity inside textract scope container.
I am giving the path of the document as shown in the image below.
AWS Textract usually picks up the files from Bucket. So, it’s better to upload the files in the bucket using the official azure package than use the Textract package to work on the same file.
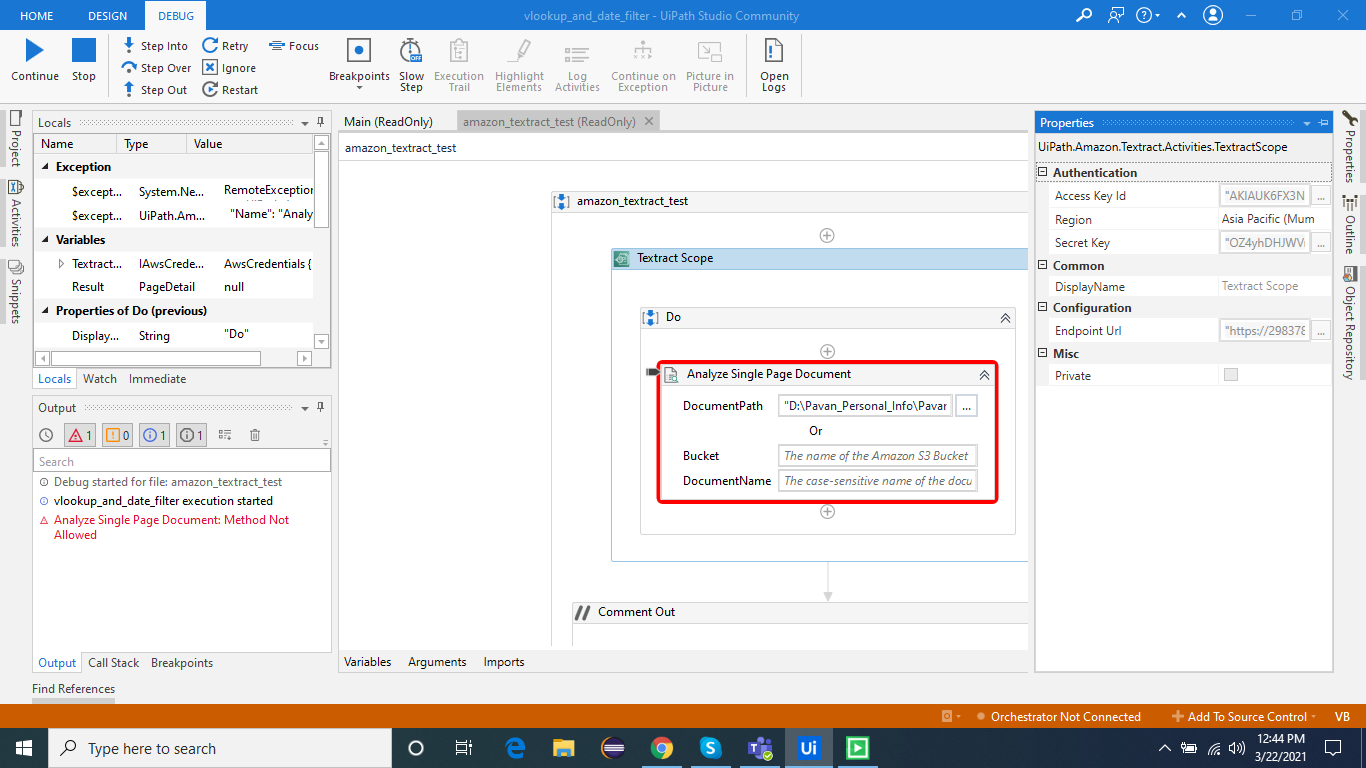
Also, make sure that the region that you selected is right. Also since you are in Textract scope I don’t think you have to provide an Endpoint URL.
Thanks for responding @Ishmeet_Bindra , I am not sure I follow you, because as per the documentations I have read, there are 2 ways to work with aws textract.
ingest the document
Pick from the Bucket.
I am not sure if your suggestion/solution helps me achieve the 1st case.