Let us introduce the next changes
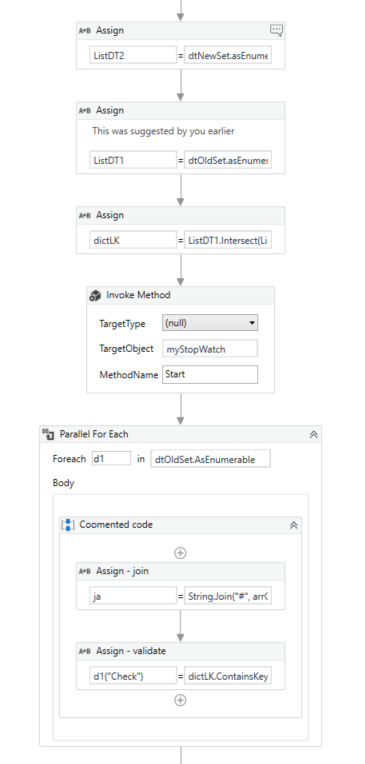
we are creating lists with the concatenated strings from dtold, dtnew
and creating a dictionary of only the items common in both lists
dtNewSet.asEnumerable.Select(Function (x) String.Join(“#”, arrColSet.Select(Function (k) x(k).toString.ToLower.Trim))).Distinct().toList
dtOldSet.asEnumerable.Select(Function (x) String.Join(“#”, arrColSet.Select(Function (k) x(k).toString.ToLower.Trim))).Distinct().toList
ListDT1.Intersect(ListDT2).ToDictionary(Function (x) x, Function (x) true)
then we simplified the processing by keeping the ja string
and using the containskey result for the column value update.
(it is writing now “True”, “False” instead of yes, no (we are interested in speed currently)
Important to know about the intersect, it is is deduplicating as well. This needs to be respected when we need to keep it as well ( find matches)

Summary of the last optmization actions:
- reduce the checklist
- shift to dictionary containsKey as we want to check if this will be faster instead of list.contains
Result: Reducing the execution time from 24+ hrs to 10-20 secs
Post edit PREVIEW
General Analysis Pattern for Performance Optimization
When the execution time is to optimize following general actions can be applied:
Cleansing
- remove any unneeded actions e.g. Log messages / Write Line… from the core block, which needs to be optimized on its execution
Measurement
- surround the core block with a Stopwatch and trace the execution time
- run the core block and cancel it, when the execution is taking too long time
Data Volume Reduction
- Apply techniques like using take(x), reduced Test Data Set to retrieve an initial understanding of the core block execution timings and interpolate it to the full data volume
Parallelization
- check and enable the parallel execution of the core block if possible. Maybe the core block has to be rewritten or to be modified
Isolation
- Isolate the time consuming parts within the core block
Optimization
- replace the time consuming parts with alternates and run again test series
Finalization
- Once the optimized format / core block implementation is found run and measure it on the entire data volume