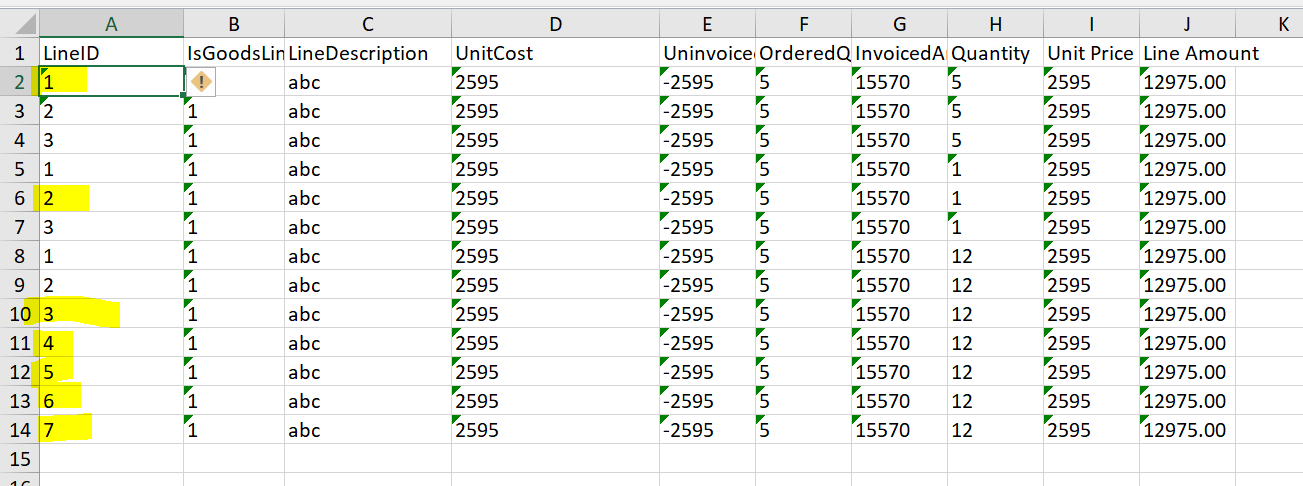
I want to delete the rows in which the line ids are repeating in the below pattern -
I want to pick the first row with line id = 1
Then it should pick row with line id = 2 but it should be the next to next row with line id =2
Then it should pick the row with line id = 3 but it should be the next to next row with line id = 3
and rest repeating rows should be deleted
So in the final table I should get values that are marked in yellow .
Please help me in this since this is very critical for our project.
May we ask you to check the following requirement definition item:
it is supposed to take for 2: excel row 6 as it is the following 2 to the first occurrence (excel row 3)
But we don’t see the rules applied for the case 1
Excel row 2 vs. Excel row 5
so maybe a more clear rewriting the requirements with more specifics is needed. Also we would recommend to include the definition of handling the non duplicated ids