I have been struggling to get the complete URL using Data Scrapping wizard. My expected URL should be displayed as “https://www.walgreens.com/article714”. However, the wizard is pulling as “/article714” which doesn’t serve my purpose.
Infact, the demo videos on UI path Data Scrapping show complete URL, but when I tried, it pulls only partial URL like I mentioned above. Any thoughts?
Would you mind providing the website where the table is located?
Using the Data Scraper, you can either choose the option
“You selected a table cell, would you like to extract the data from the whole table?”
or using the Extract Wizard to define each column at a time. At the Configure Columns option of the Extract Wizard, you can also choose the “Extract URL” checkbox for any columns with URL in it. This should help you extract the entire URL.
I am using the extract wizard and have choosen “Extract URL”. But still all the URL’s that is extracted is missing this part “https://www.discountcontactlenses.com”
I am trying to extract all 21 Product URL’s from the website mentioned below:
The UI path is pulling the URL as mentioned below which is incorrect
/discount-contacts/acuvue-oasys-1-day-for-astigmatism-30-pack-contact-lenses/714
/discount-contacts/acuvue-vita-contact-lenses/687
The problem here is that the website (or any related similar website) is using a relative path, here’s an excerpt from the html of the webpage:
<a href=“/discount-contacts/acuvue-vita-for-astigmatism-contact-lenses/718”> …
A work-around for this is a bit tricky, but definitely doable.
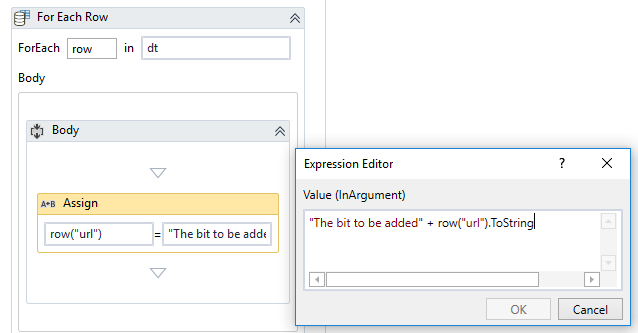
The Extract Table activity should output to an ExtractDT variable. Using a for-each row of this DataTable, you can append the necessary “https://www.discountcontactlenses.com” to the URL col for a comlpete url path you can use.
Thanks Chen… I tried with your suggestion and was able to append URL for a single column. Appreciate if you can help in implementing for each loop to have the URL for all the data in column 2. I have attached the test fileTestURL.xaml (12.5 KB)
Something like this should work, although you don’t necessarily need to export to Excel either and just work within the DataTable variable context. TestURL.xaml (13.4 KB)
Thanks, Long
I am having some issues with Data Scrapping wizard, wish you could lend me some help.
The issue is while execution, the wizard is not fetching all the result as it need to be.
In my case, I need data from a eCommerce website - Flipkart.com. I need product Name, URL, Price for a product, say refrigerator. The website displays 572 results, while csv file I am writing gives an output of less rows. It was 526 once, then it was 552 another time. It is scrapping till the last page, not like missing a page, instead missing rows in between.
I tried this with multiple products but I am not getting accurate number of results.
Please let me know if anyone has faced same issue and knows the solution or why it is happening.