@Daun
I analyzed your scenario and observed following:
- A loaded product page has the icons and only the first Image information available
- once hovering over all icons the other image information is post loaded and available as well
A look into the pagestructure:
Icons:

Image infos after hovering:

So the retrieval process could be organized as following:
- hover over all icons
- retrieve the urls
- download the images by url info
the implementation:

- attach browser
- retrieve icons listitems with find children activity
- hover over all icons
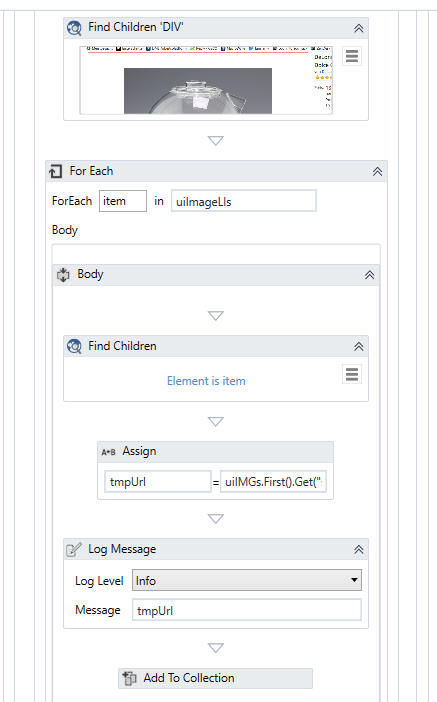
- retrieve all images (now loaded due we had done the hover)
- retrieve url via src attribute
- add url to a string list

- iterate over all urls
- load image by url with the help webrequest
- save image
The last part and saving via webrequest was just done for quick prototyping. Maybe a download via url, navigate to, save as … is more preferable, but it is up to you which procedure you want to use and to work out on production quality level (syncronizing on download progress, exception handling etc)
Demo XAML is here:
Daun.xaml (18.6 KB)
Kindly Note:
- on entry there is a Messagebox to omit page loading delays, change it once you integrate it into your flow
- feel free to shift to other browser (currently it is setup on firefox) - rework this on attach browser
- modify the path of images downloads and maybe separate it by products
Let us know your feedback