Hi @Daun,
It’s not so complicated but it requieres a little bit of knowleage about selectors. As you can see in this screenshot if I press edit in a simple click button it will show me the selector. In the image you can see the index, the first image starts at index 2.
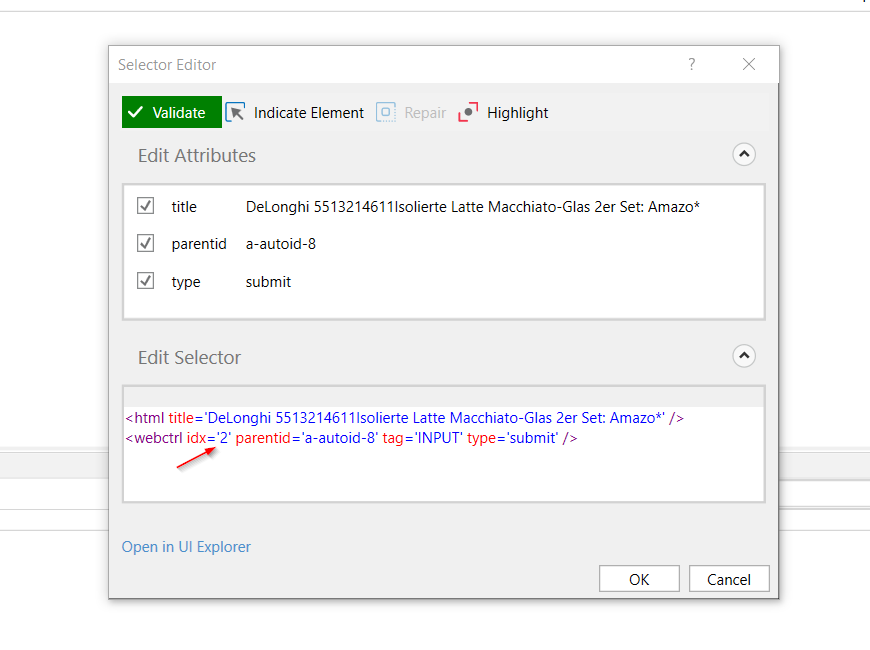
So you will do a while activity and keep incrementing that number and using right click to download. If you’re selector fails it means that it’s because there’s no more images. So once it fails the process should stop or go to the next URL.
See this post if you wish to know about how to enter variables in selectors: