Hi everybody,
I’m trying to use the form extractor to extract a few fields from an old Italian ID Card (not the plastic one). The scanned document is a 2 pages grayscale 300dpi PDF. I’m using this file (a non redacted version of course): ID-card-redacted.pdf (1.5 MB) both for the template creation and as a document to extract the data from, so in theory the template matches the document 100% since it’s the same file.
I’ve used anchors to define the two fields I want to extract. It should be easy looking at the tutorials and docs.
When running, it recognizes the two pages correctly, but it does not extract the “Nome” field and wrongly extracts the “Cognome”. I don’t understand why. I’ve tried to change the anchors and also to add more than one anchor for each field: in the latter case even the Cognome is not extracted…
Here follows two screenshots from the template manager:
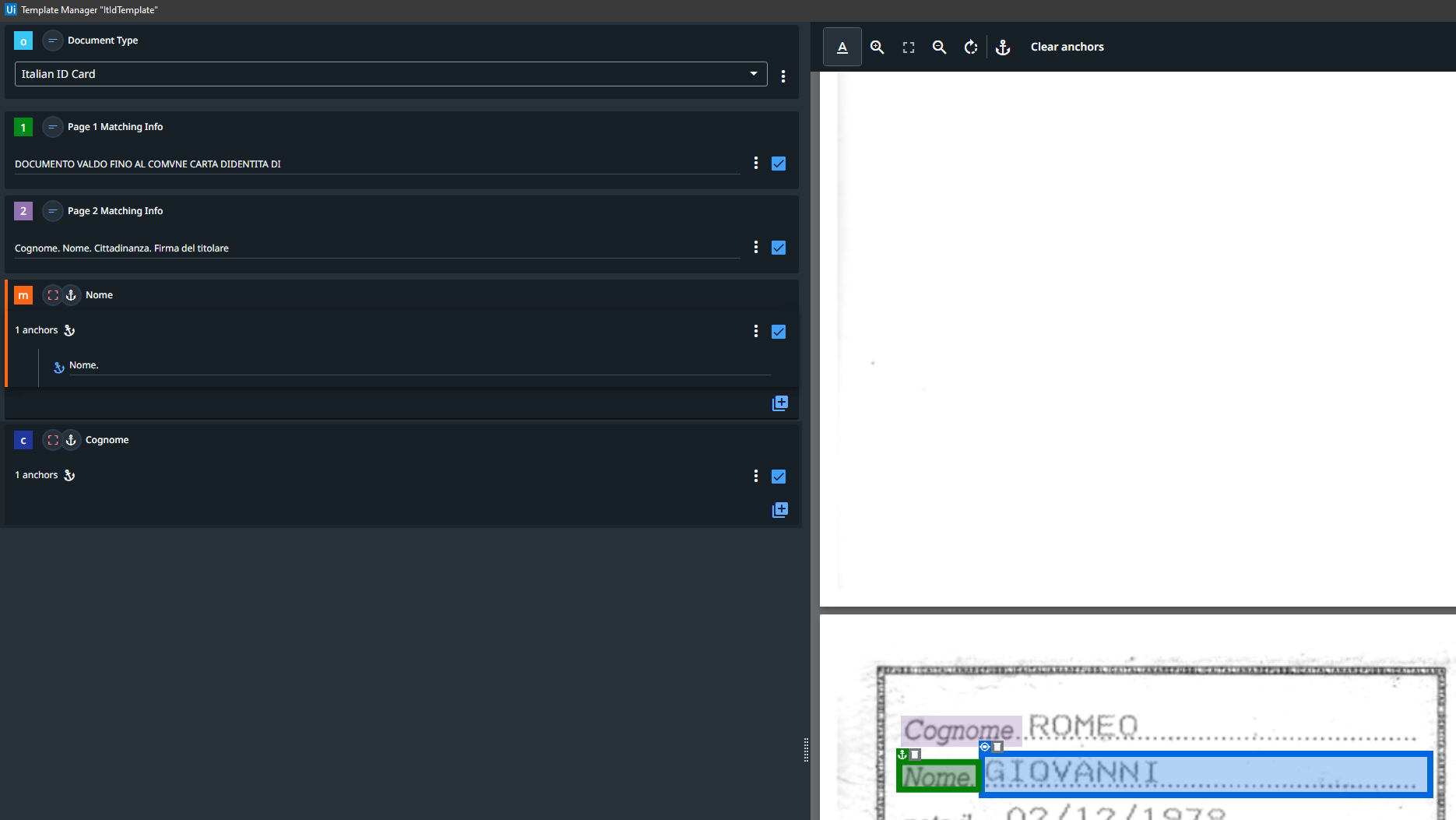
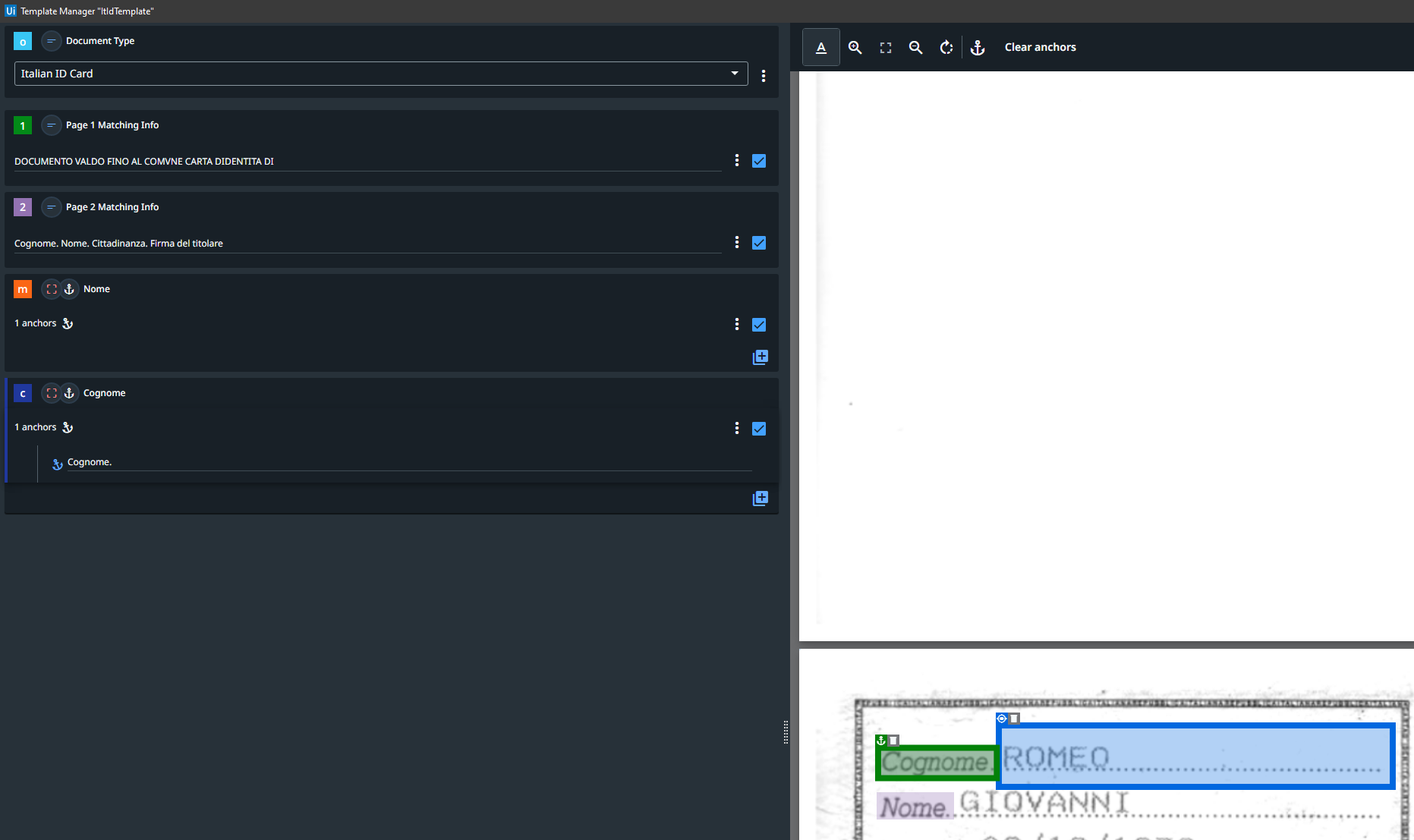
Using those two anchors, here the result from the validation station (the extracted Cognome filed value is surreal…):

Any idea?
Thanks.