I’m very happy to ask my first question… hope that you could help me.
I’m working on a regex to work on this TXT file :
CLASS C ADT=017 CHD=001
NORMAL ADT=017 CHD=001
CLASS M ADT=151 CHD=011 INF=001
NOML ADT=062 CHD=004
VGML ADT=001
My objectives :
I must ignore CLASS… lines and ------------- lines.
I must scrap complete others lines (ex : NORMAL ADT=017 CHD=001 or VGML ADT=001)
I’ve created this REGEX which works on regexr.com…
^(?!CLASS)((?=([a-zA-Z]{4,6}))(.*?)((?<=[a-zA-Z]{3}=[0-9]{3})$|(?<=[a-zA-Z]{3}=[0-9]{3} [a-zA-Z]{3}=[0-9]{3})$))
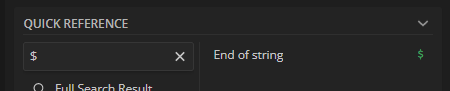
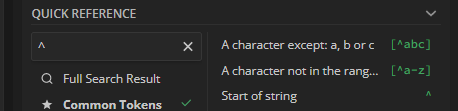
But when I used it in UI Path, it’s doesn’t works. Maybe it’s related to ^ and $
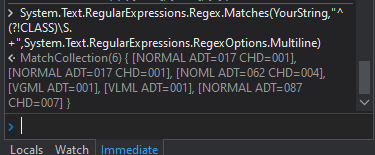
My declaration on UI path
System.Text.RegularExpressions.Regex.Matches(txtLine,“(?!CLASS)((?=([a-zA-Z]{4,6}))(.*?)((?<=[a-zA-Z]{3}=[0-9a{3})$|(?<=[a-zA-Z]{3}=[0-9]{3} [a-zA-Z]{3}=[0-9]{3})$))”)
I’ve found a more simple solution …
-Split the file into an array
-Iterate on each line by using a more simple regex :
(?![CLASS])(?=([a-zA-Z]{4,6}))(.*?)([a-zA-Z]{3}=[0-9]{3})
-If this regex return results that’s means that I could apply my process : I don’t need to capture the complete line with my regex, for that, I could use the line object.